git(1) est un outil de version control, c’est-à-dire de gestion de code sous formes de versions.
Il est utilisé pour sauvegarder chaque version d’un code source,
depuis sa création jusqu’à la dernière version.
Il est également très utile dans le cas où plusieurs programmeurs travaillent sur le même projet,
car il permet de fusionner les modifications apportées par chaque membre de l’équipe
et d’éviter les conflits de code, par exemple un fichier qui aurait été modifié conjointement
par 2 personnes.
Il est extrêmement utilisé en pratique, et permet de faciliter grandement
la gestion du code source lors de projets de taille relativement grande,
ou comprenant plusieurs programmeurs.
git(1) a été développé initialement pour la gestion du code source du kernel Linux.
Il est aussi utilisé pour la gestion des sources de ce document
depuis https://github.com/obonaventure/SyllabusC.
On l’utilise le plus souvent à l’aide de l’utilitaire git(1) mais il
existe aussi des
applications graphiques.
Le code source est sauvegardé dans un dépôt, ou repository, qui est simplement
un dossier contenant le code, et auquel chaque développeur a accès.
Ce repository contient un historique de toutes les versions du code,
depuis sa création.
Chacune des différentes versions est enregistrée dans un commit,
qui représente les modifications apportées aux différents fichiers du projet
depuis la version précédente.
On sait ainsi facilement voir ce qui a changé entre deux versions (pas spécialement
une version et la suivante) et même restaurer l’état de certains
fichiers à une version sauvegardée dans un commit. Du coup, si vous
utilisez git(1) pour un projet, vous ne pouvez jamais perdre plus
que les changements que vous n’avez pas encore committé. Toutes les
versions du codes déjà committées sont sauvegardées et facilement
accessibles. Cette garantie est extrêmement précieuse et constitue à
elle seule une raison suffisante d’utiliser git(1) pour tous vos
projets.
git(1) est souvent utilisé conjointement avec une plateforme en ligne,
comme GitHub ou GitLab (via la Forge UCLouvain),
qui permet de centraliser le code source, pour que tous les collaborateurs
puissent récupérer la dernière version, et qui permet également de consulter
le code source en ligne.
Lorsqu’on utilise git(1), chaque commit est documenté en fournissant le nom de l’auteur,
son email, un commentaire et une description (optionnelle).
Pour ne pas devoir spécifier le nom et l’email à chaque fois,
il est possible de configurer git(1) pour qu’il les stocke et les utilise pour chaque commit.
Pour ce faire, il suffit d’utiliser la commande git-config(1):
L’option --global signifie que ces données seront utilisées pour chaque repository
sur la machine. En enlevant l’option, les données seront donc uniquement utilisées
pour le repository courant.
La première étape pour profiter des capacités de git(1) pour un projet,
est de créer un repository qui contiendra le code source du projet.
La façon la plus simple de faire est de créer le repository depuis la plateforme en ligne (GitHub ou GitLab),
puis le cloner en local.
Pour ce faire, la première étape est de créer le repository sur la plateforme en ligne.
Cela est relativement simple et ne sera pas décrit dans ce document.
Ce repository sera appelé remote, car il n’est pas situé en local, mais sur
un serveur distant accessible depuis l’Internet, ce qui permet à chaque
utilisateur de le consulter pour obtenir la dernière version du code source.
Une fois créé, il faut récupérer le lien du repository sur la page web du projet.
Le lien peut être sous forme HTTPS ou SSH.
Le premier est le choix de base, et le second est choisi pour utiliser une clé ssh
pour s’identifier (voir la section SSH du syllabus pour plus d’informations).
Ensuite, il faut cloner le repository en local, avec la commande git-clone(1):
La manière la plus simple d’utiliser git(1) est de façon linéaire,
c’est-à-dire que chaque version du code (chaque commit) sera une modification de la précédente,
par addition, modification, ou suppression de fichiers.
Dans ce cas, après la création du repository contenant le projet,
le travail sur le code source suit un schéma,
qui est répété pour chaque modification, et qui est le suivant:
Récupération du dernier commit (gitpull)
Modification du code source
Ajout des modifications au commit (gitadd)
Sauvegarde du commit (gitcommit)
Publication des changements sur le remote (gitpush)
Avant de travailler sur le code, il faut récupérer en local toutes les modifications
qui auraient été apportées au remote entre temps.
En effet, si on ne récupère pas ces modifications,
des conflits peuvent apparaître, car des fichiers auraient été modifiées
en même temps dans deux copies du repository.
Pour récupérer la dernière version du remote, il suffit d’exécuter la commande git-pull(1):
$gitpull
Cette commande va appliquer les derniers commits du remote à la copie locale du repository.
Ensuite, on peux travailler sur le code et modifier les fichiers.
Lorsque des modifications ont été apportées au code, et qu’on veut les publier sur le remote
pour que tous les développeurs aient accès à la dernière version,
la première étape est de créer un commit contenant ces modifications.
Imaginons que le repository contient un fichier main.c
(qui calcule la somme des entiers de 0 à n) qui a été modifié.
On peut voir les fichiers qui ont été modifiés avec la commande git-status(1):
$gitstatus
# On branch master# Changes not staged for commit:# (use "git add <file>..." to update what will be committed)# (use "git checkout -- <file>..." to discard changes in working directory)## modified: main.c#
nochangesaddedtocommit(use"git add"and/or"git commit -a")
Avec git-diff(1), on peut voir quelles sont les lignes qui ont été
retirées (elles commencent par un -) et celles qui ont été ajoutées
(elles commencent par un +).
$ git diff
diff --git a/main.c b/main.cindex 86601ed..a9e4c4a 100644--- a/main.c+++ b/main.c@@ -2,7 +2,12 @@#include <stdlib.h>
int main (int argc, char *argv[]) {
- long int sum = 0, i, n = 42;+ long int sum = 0, i, n;+ char *end = NULL;+ n = strtol(argv[1], &end, 10);+ if (*end != '\0') {+ return EXIT_FAILURE;+ } for (i = 1; i <= n; i++) {
sum += i;
}
Si les modifications nous conviennent, il suffit ensuite d’ajouter les fichiers
modifiés au commit, avec la commande git-add(1):
$gitaddmain.c
Il est également possible d’ajouter d’un coup tous les fichiers modifiés au commit
en utilisant l’option --all de git-add(1):
$gitadd--all
Le commit a été crée, il faut maintenant le sauvegarder, puis le publier sur le remote.
Une fois que le commit a été crée, il faut le sauvegarder,
pour indiquer au repository qu’on est passé à une nouvelle version.
Pour ce faire, on utilise la commande git-commit(1):
$gitcommit
Cette commande va ouvrir un éditeur de texte pour indiquer un message
décrivant le commit.
Par défaut, l’éditeur est vim(1).
Il s’agit d’un éditeur en ligne de commande, puissant mais très compliqué à utiliser pour les débutants.
Il est possible de modifier l’éditeur par défaut en utilisant la commande git-config(1),
déjà mentionnée plus haut.
Un autre éditeur en ligne de commande, plus simple d’utilisation, est nano(1).
Pour choisir nano(1) comme éditeur par défaut, il suffit d’exécuter la commande suivante:
$gitconfig--globalcore.editornano
Cependant, ouvrir un éditeur de texte à chaque commit peut vite devenir laborieux.
En utilisant l’option -m de git-commit(1), il est possible de spécifier le message
décrivant le commit directement lors de l’appel à la commande git-commit(1):
Parmi les options de git-commit(1), il existe aussi l’option -a qui peut s’avérer très utile.
Cette option permet d’ajouter directement, lors de l’appel à git-commit(1),
toutes les modifications qui auraient été apportées à des fichiers
déjà enregistrés dans le repository.
Si de nouveaux fichiers ont été créés, l’option -a ne les prendra pas en compte,
et il faudra alors passer par la commande git-add(1).
Il est finalement possible de combiner les options -m et -a, en utilisant l’option -am.
Cette option permet donc, en une seule commande, d’ajouter toutes les modifications
apportées aux fichiers déjà suivis, et de préciser le message du commit, de la façon suivante:
Pour que tous les développeurs soient en mesure de voir les dernières modifications
qui auraient été apportées en local, il faut que chaque développeur,
après avoir créé et enregistré un commit, le publie sur le remote,
qui est accessible par tous les développeurs via l’Internet.
Pour ce faire, on utilise la commande git-push(1):
De cette manière, chaque développeur qui voudrait à son tour apporter des modifications au projet,
peut appliquer les mêmes étapes, et le remote contiendra toujours la dernière version du code.
En résumé, les étapes sont:
Lorsque plusieurs développeurs travaillent sur un même projet, il est possible qu’il
apportent des modifications au code en même temps.
Dans ce cas, pour le second développeur voulant push ses modifications,
le push sera rejeté:
Cela est dû a fait que le remote a été modifié entre temps par un autre développeur,
et donc que le dernier commit n’est pas le même sur le repository local et le remote.
Pour régler ce problème, on commence par faire un gitpull.
Deux cas de figure peuvent alors apparaître.
Le premier cas, le plus simple, arrive lorsque les deux développeurs ont modifié des fichiers différents.
Dans ce cas, le pull va réussir à fusionner les deux versions du repository,
et produire un merge (une fusion).
Un éditeur de texte s’ouvrira pour indiquer un message relatif au merge,
et une fois ce message écrit, le merge sera effectué:
Il ne reste plus qu’à faire un gitpush pour que le merge soit
publié sur le remote.
Le deuxième cas possible arrive lorsque les deux développeurs ont modifié le même fichier
(par exemple main.c).
Dans ce cas, le gitpull n’arrivera pas à merge automatiquement:
La ligne située entre le marqueur HEAD et la ligne de séparation
est la version présente en local,
tandis que la ligne située après la ligne de séparation est celle présente sur le remote.
Il est possible de retrouver quels sont les fichiers en conflit en utilisant git-status(1):
$gitstatus
# On branch master# You have unmerged paths.# (fix conflicts and run "git commit")## Unmerged paths:# (use "git add <file>..." to mark resolution)## both modified: main.c#
nochangesaddedtocommit(use"git add"and/or"git commit -a")
Il suffit alors d’éditer le fichier en question, et de ne garder que le contenu voulu
dans le fichier:
La puissance de git(1) vient du fait qu’il est possible de créer des historiques
non-linéaires, plus complexes que l’historique linéaire simple décrit jusqu’à présent.
Pour cela, on utilise le concept de branches,
qui représentent différentes modifications en parallèle du code source.
Un repository git(1) est divisé en branches, qui représentent des évolutions
différentes en parallèle du repository.
Chaque commit est appliqué sur une seule branche.
De cette manière, les branches sont une bonne manière de développer de nouvelles
fonctionnalités, sans compromettre une version fonctionnelle du code.
Lors de l’utilisation linéaire de git(1) décrite ci-dessus, toutes les modifications
apportées au code se faisaient sur une seule branche, la branche master.
Il s’agit de la branche de base, sur laquelle toutes les modifications sont apportées,
si on ne créé pas explicitement de nouvelle branche.
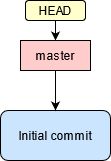
De base, l’historique d’un repository est donc le suivant:
Les commits sont représentés en bleu, et les branches en rouge.
L’indication HEAD représente l’état actuel du repository sur la copie locale.
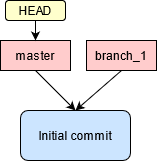
Pour créer une nouvelle branche, on utilise la commande git-branch(1),
en spécifiant le nom de la nouvelle branche. On peut aussi utiliser cette commande
sans argument pour montrer toutes les branches existantes,
avec un symbole * pour indiquer la branche active (donc là où est situé le marqueur HEAD):
Pour supprimer une branche, on utilise la commande git-branch(1),
avec l’option -d, et en spécifiant le nom de la branche à supprimer:
$gitbranch-dbranch_1
$gitbranch
*master
La création d’une branche ne change pas la branche active,
ce qui signifie que les modifications apportées au code le seront toujours sur la branche master.
Pour changer de branche active, il faut utiliser la commande git-checkout(1):
Avec cette commande, le pointeur HEAD a été modifié, et pointe maintenant vers la branche branch_1.
Désormais, les modifications seront bien apportées sur la branche branch_1.
Attention, lorsqu’on travaille sur une branche autre que master, les simples commandes
gitpush ou gitpull ne fonctionneront pas.
A la place, il faut utiliser les commandes suivantes:
gitpushoriginbranch
gitpulloriginbranch
Ces commandes fonctionnent également avec la branche master, en remplaçant le nom
de la branche par master.
En général, on utilise les branches pour développer de nouvelles fonctionnalités
sans risquer de compromettre la base fonctionnelle du code.
Lorsque la fonctionnalité est finie et est fonctionnelle,
on veut pouvoir fusionner la branche de base (master) avec la branche utilisée
pour développer la fonctionnalité (soit branch),
en appliquant un merge.
Pour ce faire, il y a deux possibilités:
Utiliser l’interface web de la plateforme (GitLab ou GitHub).
Cette possibilité est la plus simple.
La première possibilité est très simple.
Un exemple sera donné ici avec GitLab, et est très similaire avec GitHub.
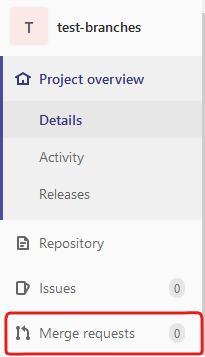
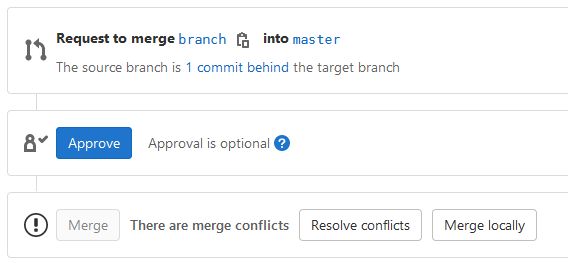
Tout d’abord, depuis la page du repository, aller sur la page « Merge requests »
( »Pull requests » sur GitHub):
Créez une nouvelle merge/pull request.
Il faut ensuite choisir les branches source et cible (target).
La branche source sera celle avec la nouvelle fonctionnalité,
dans notre cas la branche branch, tandis que la branche cible
sera la branche de base, dans notre cas la branche master.
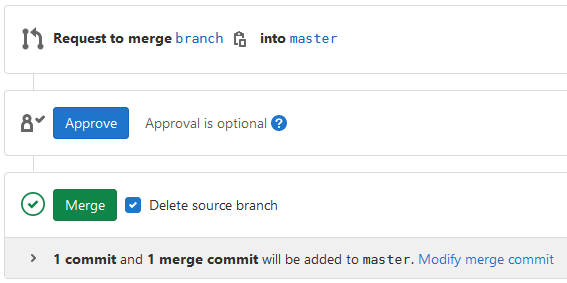
Il est possible d’inclure une description à la merge request,
et de configurer plusieurs options, comme la personne qui doit s’occuper de la merge request,
ou le fait que la branche source sera supprimée ou pas après la fusion.
Une fois la merge request créée, s’il n’y a pas de conflit,
les branches peuvent être fusionnées automatiquement:
Ces conflits peuvent être résolus directement depuis l’interface web,
ou en fusionnant les branches localement, puis en réglant les conflits
comme expliqué précédemment.
Il est également possible de fusionner des branches localement,
en utilisant la ligne de commande.
Pour cela, on va utiliser la commande git-merge(1), depuis la branche cible (master),
pour la fusionner avec la branche source (branch).
Si il n’y a pas de conflit, la fusion est automatique:
Si les mêmes fichiers ont été modifiés sur les deux branches, il y a conflit,
et il faut donc résoudre ces conflits comme expliqué précédemment.
Ici, il y a conflit sur le fichier branch.txt:
Pour afficher l’historique, outre l’outil utilisé pour faire les
illustrations de ce cours que vous pouvez retrouver
https://github.com/blegat/git-dot,
il existe la commande git-log(1).
Elle est très flexible comme on va le voir.
gitlog affiche simplement l’historique à partir de HEAD
Mais on peut aussi demander d’afficher les modifications pour chaque commit
avec l’option -p
$ git log -p
commit 0dd6cd7e6ecf01b638cd631697bf9690baedcf20
Merge: eda36d7 6fd2e9b
Author: Benoît Legat <benoit.legat@gmail.com>
Date: Sun Aug 18 15:29:53 2013 +0200
Merge branch 'universal'
Conflicts:
main.c
commit 6fd2e9bfa199fc3dbca4df87d225e35553d6cd79
Author: Benoît Legat <benoit.legat@gmail.com>
Date: Sun Aug 18 15:06:14 2013 +0200
Fix SIGSEV without args
diff --git a/main.c b/main.cindex 8ccfa11..f90b795 100644--- a/main.c+++ b/main.c@@ -9,7 +9,7 @@// main function
int main (int argc, char *argv[]) {
// main function
int main (int argc, char *argv[]) {
- if (strncmp(argv[1], "--alien", 8) == 0) {+ if (argc > 1 && strncmp(argv[1], "--alien", 8) == 0) { printf("Hello universe!\n");
} else {
printf("Hello world!\n");
commit eda36d79fd48561dce781328290d40990e74a758
Author: Benoît Legat <benoit.legat@gmail.com>
Date: Sun Aug 18 14:58:29 2013 +0200
Add pid/ppid info
diff --git a/main.c b/main.cindex 8381ce0..b9043af 100644--- a/main.c+++ b/main.c@@ -5,9 +5,11 @@// includes
#include <stdio.h>
#include <stdlib.h>
+#include <unistd.h>// main function
int main () {
+ printf("pid: %u, ppid: %u\n", getpid(), getppid()); printf("Hello world!\n");
return EXIT_SUCCESS;
}
Il existe encore plein d’autres options comme --stat qui se contente
de lister les fichiers qui ont changés.
En les combinant on peut obtenir des résultats intéressants comme ci-dessous
Sauvegarder des modifications hors de l’historique¶
On a vu que certaines opérations comme git-checkout(1) nécessitent
de ne pas avoir de modifications en conflit avec l’opération.
git-stash(1) permet de sauvegarder ces modifications pour qu’elles ne soient
plus dans le working directory mais qu’elles ne soient pas perdues.
On peut ensuite les appliquer à nouveau avec gitstashapply puis les effacer
avec gitstashdrop.
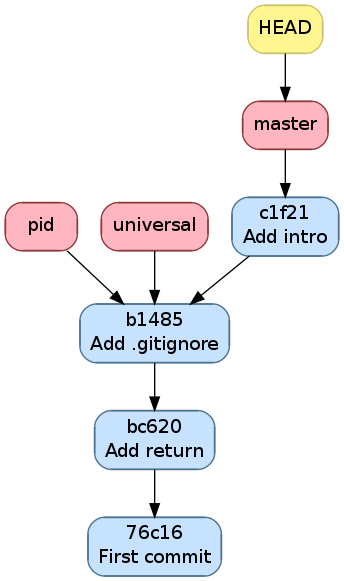
Reprenons notre exemple de Changer la branche active illustré par la figure
suivante
Historique après avoir ajouté un commentaire d’introduction¶
$gitcheckoutpid
Switchedtobranch'pid'
$echo"42">>main.c
$echo"42">>.gitignore
$gitstash
SavedworkingdirectoryandindexstateWIPonpid:b14855eAdd.gitignore
HEADisnowatb14855eAdd.gitignore
$gitcheckoutmaster
Switchedtobranch'master'
$gitstashapply
Auto-mergingmain.c
# On branch master# Changes not staged for commit:# (use "git add <file>..." to update what will be committed)# (use "git checkout -- <file>..." to discard changes in working directory)## modified: .gitignore# modified: main.c#
nochangesaddedtocommit(use"git add"and/or"git commit -a")
Si on a oublié d’ajouter des modifications dans le dernier commit et
qu’on ne l’a pas encore pushé, on peut facilement les rajouter.
Il suffit de donner l’option --amend à git-commit(1).
Il ajoutera alors les modifications au commit actuel au lieu d’en créer un
nouveau.
On peut aussi annuler le dernier commit avec gitresetHEAD^.
git(1) permet aussi de construire un commit qui a l’effet inverse d’un autre
avec git-revert(1).
Ce dernier construit un commit qui annulera l’effet d’un autre commit.
Voyons tout ça par un exemple qui pourrait être le code de Deep Thought.
run:answerecho"The answer is `./answer`"answer:main.cgcc-oanswermain.c
si bien qu’on a
$make
gcc-oanswermain.c
echo"The answer is `./answer`"
Theansweris42
$make
echo"The answer is `./answer`"
Theansweris42
$touchmain.c
$make
gcc-oanswermain.c
echo"The answer is `./answer`"
Theansweris42
et un fichier .gitignore avec comme seul ligne answer.
Commençons par committer main.c et .gitignore en oubliant le
Makefile.
$gitinit
InitializedemptyGitrepositoryin/path/to_project/.git/
$gitstatus
# On branch master## Initial commit## Untracked files:# (use "git add <file>..." to include in what will be committed)## .gitignore# Makefile# main.c
nothingaddedtocommitbutuntrackedfilespresent(use"git add"totrack)
$gitadd.gitignoremain.c
$gitcommit-m"First commit"[master(root-commit)54e48c9]Firstcommit
2fileschanged,10insertions(+)createmode100644.gitignore
createmode100644main.c
$gitlog--stat--oneline
54e48c9Firstcommit
.gitignore|1+
main.c|9+++++++++
2fileschanged,10insertions(+)
$gitstatus
# On branch master# Untracked files:# (use "git add <file>..." to include in what will be committed)## Makefile
nothingaddedtocommitbutuntrackedfilespresent(use"git add"totrack)
On pourrait très bien faire un nouveau commit contenant le Makefile
mais si, pour une quelconque raison,
on aimerait l’ajouter dans le commit précédent,
on peut le faire comme suit
On voit qu’aucun commit n’a été créé mais c’est le commit précédent qui
a été modifié.
Ajoutons maintenant un check de la valeur retournée par malloc(3) pour gérer
les cas limites
git(1) permet de garder des traces des nombreux changements qui ont été effectué au
cours de l’évolution d’un programme. Il contient d’ailleurs un outil très
puissant vous permettant de retrouver la source de certaines erreurs, pourvu que
les changements soient faits par petits commits : git-bisect(1).
Supposez que vous ayez introduit une fonctionnalité dans votre programme. Tout
allait alors pour le mieux. Quelques semaines plus tard, à votre grand dam, vous
vous rendez compte qu’elle ne fonctionne plus. Vous sillonnez tous les fichiers
qui pourraient interagir avec cette fonction, en vain. Dans le désespoir, à
l’approche de la deadline, vous succombez au nihilisme.
Avant de tout abandonner, pourtant, vous réalisez quelque chose de très
important. Ce que vous cherchez, c’est la source de l’erreur ; cela fait, la
corriger sera sans l’ombre d’un doute une tâche aisée. Si seulement il était
possible de voir à partir de quel changement le bug a été introduit…
C’est là que vous repensez à git(1) ! git(1) connaît tous les changements qui ont été
effectués, et vous permet facilement de revenir dans le passé pour vérifier si
le bug était présent à un moment donné. En outre, vous vous rappelez vos cours
d’algorithmiques et vous rendez compte que, puisque vous connaissez un point où
le bug était présent et un autre ou il ne l’était pas, vous pouvez à l’aide
d’une recherche binaire déterminer en un temps logarithmique (par rapport aux
nombres de révisions comprises dans l’intervalle) quelle révision a introduit
l’erreur.
C’est exactement l’idée derrière git-bisect(1) : vous donnez un intervalle de
commits dans lequel vous êtes certains de pouvoir trouver le vilain commit
responsable de tous vos maux, pour ensuite le corriger. Vous pouvez même
entièrement automatiser cette tâche si vous pouvez, excellent programmeur que
vous êtes, écrire un script qui renvoie 1 si le bug est présent et 0 si tout va
bien.
Pour vous montrez comme utiliser cette fonctionnalité, et vous convaincre que
cela marche vraiment, et pas seulement dans des exemples fabriqués uniquement
dans un but de démonstration, nous allons l’appliquer à un vrai programme C :
mruby, une implémentation d’un langage correspondant à un sous-ensemble de Ruby.
Intéressons nous à un des problèmes qui a été rapporté par un utilisateur. Si vous lisez cette page, vous
verrez qu’en plus de décrire le problème, il mentionne le commit à partir duquel
il rencontre l’erreur. Si vous regardez aussi le commit qui l’a corrigée, vous
verrez que le développeur a bien dû changer une ligne introduite dans le commit
qui avait été accusé par l’utilisateur.
Mettons nous dans la peau de l’utilisateur qui a trouvé le bug, et tentons nous
aussi d’en trouver la cause, en utilisant git(1) . D’abord, il nous faut obtenir le
dépôt sur notre machine (vous aurez besoin de Ruby afin de pouvoir tester),
et revenir dans le passé puisque, depuis, l’erreur a été corrigée.
C’est le moment de commencer. Il faut d’abord dire à git(1) que nous désirons
démarrer une bissection et que le commit actuel est « mauvais », c’est à dire
que le bug est présent. Ceci est fait en utilisant les deux lignes suivantes,
dans l’ordre :
$ gitbisectstart
$ gitbisectbad
Regardons ce qu’il en était quelque mois auparavant (remarquez qu’il faut
utiliser makeclean pour s’assurer de tout recompiler ici) :
$ gitcheckout3a27e9189aba3336a563f1d29d95ab53a034a6f5
Previous HEAD position was 7ca2763... write_debug_record should dump info recursively; close #1581HEAD is now at 3a27e91... move (void) cast after declarations$ makeclean&&make&&./bin/mruby~/code/test.rb
(...)trace: [3] /home/kilian/code/rb/test.rb:9:in A.c [2] /home/kilian/code/rb/test.rb:6:in A.b [1] /home/kilian/code/rb/test.rb:3:in A.a [0] /home/kilian/code/rb/test.rb:13/home/kilian/code/rb/test.rb:9: undefined method 'd' for #<A:0x165d2c0> (NoMethodError)
Cette fois-ci, tout va bien. Nous pouvons donc en informer git(1) :
$ gitbisectgood
Bisecting: 116 revisions left to test after this (roughly 7 steps)[fe1f121640fbe94ad2e7fabf0b9cb8fdd4ae0e02] Merge pull request #1512 from wasabiz/eliminate-mrb-intern
Ici, git(1) nous dit combien de révisions il reste à vérifier dans l’intervalle en
plus de nous donner une estimation du nombre d’étapes que cela prendra. Il nous
informe aussi de la révision vers laquelle il nous a déplacé. Nous pouvons donc
réitérer notre test et en communiquer le résultat à git(1) :
$ makeclean&&make&&./bin/mruby~/code/test.rb
(...)trace: [3] /home/kilian/code/rb/test.rb:9:in A.c [2] /home/kilian/code/rb/test.rb:6:in A.b [1] /home/kilian/code/rb/test.rb:3:in A.a [0] /home/kilian/code/rb/test.rb:13/home/kilian/code/rb/test.rb:9: undefined method 'd' for #<A:0x165d2c0> (NoMethodError)$ gitbisectgood
Bisecting: 58 revisions left to test after this (roughly 6 steps)[af03812877c914de787e70735eb89084434b21f1] add mrb_ary_modify(mrb,a); you have to ensure mrb_value a to be an array; ref #1554
Si nous réessayons, nous allons nous rendre compte que notre teste échoue à
présent (il manque la ligne [1]): nous somme allés trop loin dans le
futur. Il nous faudra donc dire à git(1) que la révision est mauvaise.
$ makeclean&&make&&./bin/mruby~/code/test.rb
(...)trace: [3] /home/kilian/code/rb/test.rb:9:in A.c [2] /home/kilian/code/rb/test.rb:6:in A.b [0] /home/kilian/code/rb/test.rb:13/home/kilian/code/rb/test.rb:9: undefined method 'd' for #<A:0x165d2c0> (NoMethodError)$ gitbisectbad
Bisecting: 28 revisions left to test after this (roughly 5 steps)[9b2f4c4423ed11f12d6393ae1f0dd4fe3e51ffa0] move declarations to the beginning of blocks
Si vous continuez à appliquer cette procédure, vous allez finir par trouver la
révision fautive, et git(1) nous donnera l’information que nous recherchions, comme
par magie :
$ gitbisectbad
Bisecting: 0 revisions left to test after this (roughly 0 steps)[a7c9a71684fccf8121f16803f8e3d758f0dea001] better error position display$ makeclean&&make&&./bin/mruby~/code/rb/test.rb
(...)trace: [3] /home/kilian/code/rb/test.rb:9:in A.c [2] /home/kilian/code/rb/test.rb:6:in A.b [0] /home/kilian/code/rb/test.rb:13/home/kilian/code/rb/test.rb:9: undefined method 'd' for #<A:0x1088160> (NoMethodError)$ gitbisectbad
a7c9a71684fccf8121f16803f8e3d758f0dea001 is the first bad commitcommit a7c9a71684fccf8121f16803f8e3d758f0dea001Author: Yukihiro "Matz" Matsumoto <matz@ruby-lang.org>Date: Tue Oct 15 12:49:41 2013 +0900 better error position display:040000 040000 67b00e2d4f6acadc0474e00fc0f5e6e13673c64a 036eb9c3b9960613bde3882b7a88ac6cabc56253 M include:040000 040000 5040dd346fea4d8f476d26ad2ede0dc49ca368cd 903f2d954d8686e7bfa7bcf5d83b80b5beb4899f M src
Maintenant que nous connaissons la source du problème, il ne faut pas oublier de
confirmer à git(1) que la recherche est bien terminée, et que nous désirons
remettre le dépôt dans son état normal.
$ gitbisectreset
Previous HEAD position was a7c9a71... better error position displayHEAD is now at 7ca2763... write_debug_record should dump inforecursively; close #1581
Exécuter ce test à la main est cependant répétitif, prône aux erreurs
d’inattention, et surtout très facile à automatiser. Écrivons donc un script qui
vérifie que la ligne mentionnant A.a est bien présente à chaque fois,
appelons le par exemple ~/code/sh/Iznogoud.sh. Il s’agit de renvoyer 0
si tout se passe bien et une autre valeur s’il y a un problème.
Puisque grep renvoie 1 quand il ne trouve pas de ligne contenant le motif
qu’on lui passe en argument et 0 sinon, notre script renvoie bien 1 si la sortie
de mruby ne contient pas la ligne mentionnant A.a et 0 sinon.
N’oubliez pas de changer les permissions du script pour en permettre l’exécution :
$ chmod+x~/code/sh/Iznogoud.sh
Ce test n’est en bien sûr pas infaillible, mais sera suffisant ici. Il faut
d’abord redonner à git(1) l’intervalle dans lequel se trouve la révision fautive.
$ gitbisectstart
$ gitbisectbad
$ gitcheckout3a27e9189aba3336a563f1d29d95ab53a034a6f5
Previous HEAD position was 7ca2763... write_debug_record should dump info recursively; close #1581HEAD is now at 3a27e91... move (void) cast after declarations$ gitbisectgood
Bisecting: 116 revisions left to test after this (roughly 7 steps)[fe1f121640fbe94ad2e7fabf0b9cb8fdd4ae0e02] Merge pull request #1512 from wasabiz/eliminate-mrb-intern
Il suffit maintenant d’utiliser gitbisectrun avec le nom du script pour
l’utiliser. Il est possible de rajouter d’autres arguments après le nom du
script, qui seront passés au script lors de chaque exécution. Par exemple, si
vous avez dans votre Makefile une tâche test qui renvoie 0 si tous les tests
passent et 1 si certains échouent, alors gitbisectrunmaketest
permettrait de trouver à partir de quand les tests ont cessé de fonctionner.
Si vous exécutez la ligne suivante, vous devriez bien trouver, après quelques
compilations, le même résultat qu’avant :
$ gitbisectrun~/code/sh/Iznogoud.sh
(...)a7c9a71684fccf8121f16803f8e3d758f0dea001 is the first bad commitcommit a7c9a71684fccf8121f16803f8e3d758f0dea001Author: Yukihiro "Matz" Matsumoto <matz@ruby-lang.org>Date: Tue Oct 15 12:49:41 2013 +0900 better error position display:040000 040000 67b00e2d4f6acadc0474e00fc0f5e6e13673c64a 036eb9c3b9960613bde3882b7a88ac6cabc56253 M include:040000 040000 5040dd346fea4d8f476d26ad2ede0dc49ca368cd 903f2d954d8686e7bfa7bcf5d83b80b5beb4899f M srcbisect run success
À nouveau, n’oubliez pas d’utiliser gitbisectreset avant de continuer à
travailler sur le dépôt.